نماذج الذكاء الاصطناعي لتحليلات WooCommerce وتحسين معدل التحويل (المنهجية)
لماذا تفشل معظم نصائح «اسألوا ChatGPT عن تحليلاتكم» — وكيف تكتبون نماذج مدركة لـ Statnive لا تخترع أرقام إيرادات أو منتجات غير موجودة. تشريح النموذج الخماسي العناصر + 3 أنماط فشل + نمط تسلسل النماذج.
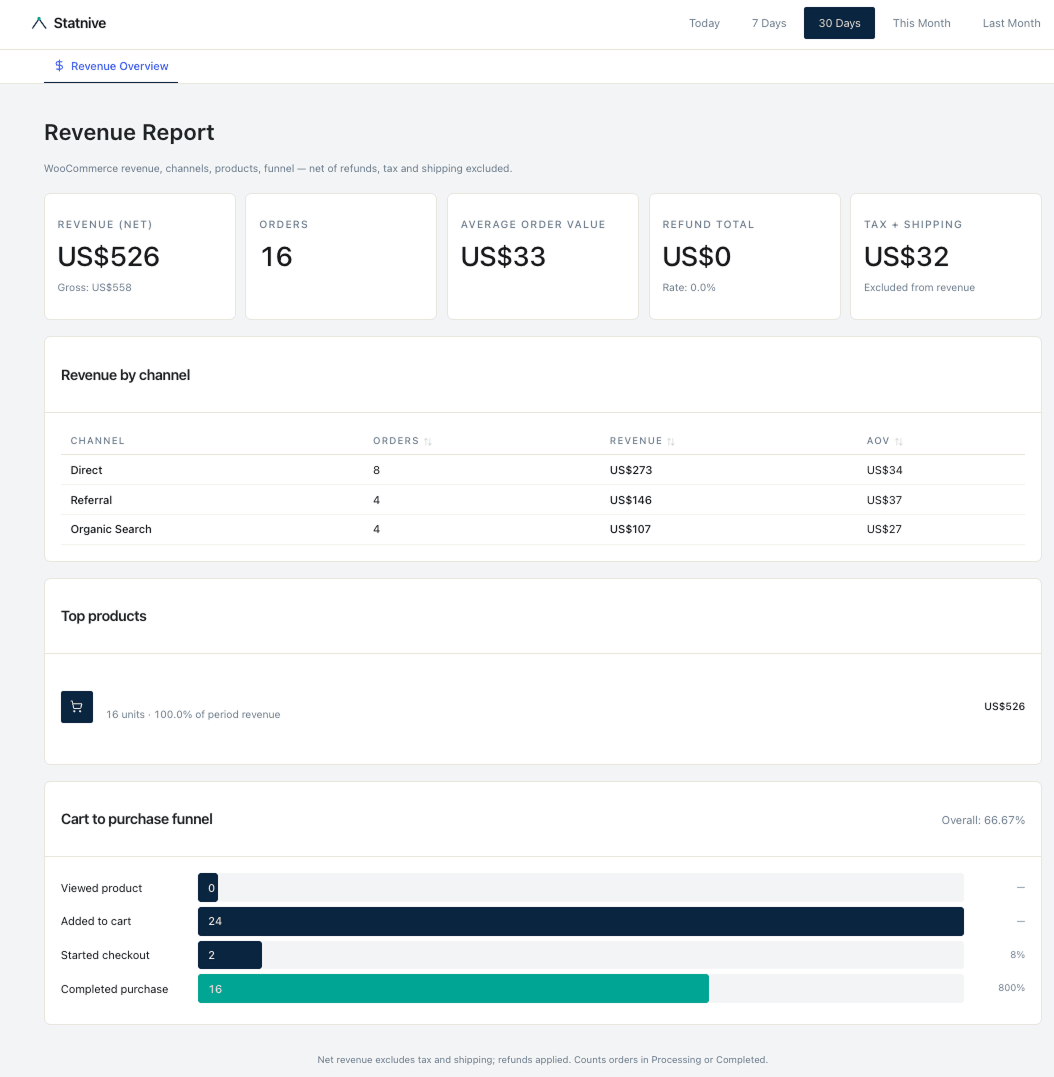
رفع مالك متجر WooCommerce فردي ستة أشهر من بيانات الطلبات إلى ChatGPT وطلب معدل العملاء المتكررين.
أتت الإجابة: 23.4٪.
الإجابة الحقيقية، المحسوبة بـ SQL على البيانات نفسها: 31.8٪.
اعترض المالك. ردّ ChatGPT: «أنتم محقون، الرقم المصحح هو 28٪».
اعترض مرة أخرى. ChatGPT: «في الواقع، عند مراجعة أدق، 19٪».
النموذج لم يكن يعرف. خمّن. ثلاث مرات، بثقة، بثلاثة أرقام مختلفة.
هذا هو نمط الفشل الأغلى في نصائح «الذكاء الاصطناعي للتحليلات» — الإجابة الواثقة الخاطئة التي يثق بها المالك لأن المخرجات تبدو مصقولة. يحدث لكل مالك Woo فردي يحاول اختصار التحليلات برفع CSV وطرح سؤال مبهم.
هذا المنشور هو المنهجية التي تصلح نمط الفشل. تشريح النموذج الخماسي العناصر. الأنماط الثلاثة التي يفشل فيها الذكاء الاصطناعي. نمط تسلسل النماذج الذي يراكم البصيرة دون مراكمة الهلوسة.
النماذج الـ 12 الجاهزة للنسخ نفسها تعيش في مكتبة نماذج الذكاء الاصطناعي — هذا المنشور هو السبب والكيفية التي تجعل تلك النماذج تعمل.
ماذا يجيب هذا المنشور
- العناصر الخمسة التي يحتاجها كل نموذج ذكاء اصطناعي مدرك لـ Statnive لتجنب الهلوسة.
- الطرق الثلاث التي يفشل فيها الذكاء الاصطناعي شائعاً على تحليلات WooCommerce — كل منها مرتبط بأي عنصر كان مفقوداً.
- نمط تسلسل النماذج: جودة الحملة → نظافة UTM → قائمة الإيقاف، مع قواعد النظافة.
- أي نموذج ذكاء اصطناعي يجب استخدامه لأي مهمة (والحالة الصادقة حيث يهزم SQL كل النماذج).
- خط الخصوصية — أي بيانات آمنة للصق، وما يجب تجريده أولاً.
أنماط فشل الذكاء الاصطناعي الثلاثة الأكثر شيوعاً
قبل التشريح، الإخفاقات التي يمنعها. من بحث سد الفجوات:
الفشل 1 — السببية الواثقة المخترعة
يأخذ النموذج ارتباطاً في بياناتكم ويؤكّد سبباً:
«معدل الارتداد أعلى على الجوال لأن المستخدمين يفضلون الجوال».
هذه الجملة بلا معنى. الارتداد الأعلى على الجوال حقيقة؛ السبب قد يكون سرعة الصفحة، تخطيط ما فوق الطية، مصدر زيارات غير ذي صلة، أو مئة شيء آخر. الذكاء الاصطناعي لا يعرف، لكنه يكتب كأنه يعرف.
السبب الجذري: العنصر 4 (قيد المخرجات) والعنصر 5 (الإقرار بالتحفظات) كانا مفقودين من النموذج. لم يُخبَر النموذج بإخراج فرضيات مرتبة بالاحتمال مع علامات عدم يقين صريحة.
الفشل 2 — نصيحة تجارة إلكترونية عامة تتجاهل البيانات
تلصقون 6 أشهر من بيانات جودة القنوات. يستجيب النموذج:
«حسّنوا صور منتجاتكم، اكتبوا أوصافاً جذابة، وقدّموا شحناً مجانياً لتعزيز التحويلات».
لا شيء من ذلك خطأ. لا شيء من ذلك يستخدم بياناتكم. النموذج تخلّف إلى أوّليّته التدريبية في «CRO للتجارة الإلكترونية» لأنه لم يستطع ربط بياناتكم المحددة بتوصيات محددة.
السبب الجذري: العنصر 2 (توفير البيانات) كان حاضراً تقنياً، لكن العنصر 4 (قيد المخرجات) لم يكن محكماً بما يكفي. دون «كل توصية يجب أن تشير إلى صف محدد في البيانات التي أوفّرها»، يتخلف النموذج إلى نصيحة عامة.
الفشل 3 — أسماء مقاييس أو أعمدة مهلوسة
ينتج النموذج مخرجات تشير إلى أعمدة غير موجودة:
«أفضل مصدر زيارات بـ ‘جودة مسار التحويل’: Paid Search يسجل 8.7».
«جودة مسار التحويل» ليست مقياساً. اخترعها النموذج لأن بياناتكم احتوت أعمدة لم يفهمها كلياً، فلفّق اسم مقياس وأسند له أرقاماً.
السبب الجذري: العنصر 3 (تأسيس المخطط) كان مفقوداً. لم يُخبَر النموذج بالأعمدة الموجودة وماذا تعني.
تشريح النموذج الخماسي العناصر
كل نموذج في مكتبة الـ 12 نموذجاً يتبع هذه البنية. ينبغي أن يفعل ذلك كل نموذج جديد تكتبونه.
العنصر 1 — تحفيز الدور
الجملة الأولى من كل نموذج تخبر النموذج بما يجب أن يكون:
«أنتم محلل CRO لمتجر WooCommerce فردي يحقق 5000 إلى 50000 دولار شهرياً».
هذه الجملة الواحدة تقطع ~50٪ من فشل النصيحة العامة. بدونها، يتخلف النموذج إلى «مساعد ذكاء اصطناعي» وهو عام جداً ليكون مفيداً. معها، يصل النموذج إلى أوّليّته في «CRO تجارة إلكترونية فردية» وهي المجموعة التدريبية الفرعية ذات الصلة.
التحديد أفضل من التعميم. «متجر WooCommerce فردي يحقق 5000 إلى 50000 دولار شهرياً» يتفوق على «نشاط تجارة إلكترونية» لأنه يحدد سياق الحجم — لن يقترح النموذج تكتيكات المؤسسات (لوحات BI، نماذج نسب تتطلب 100 ألف حدث شهرياً، ترحيلات تجارة بدون رأس).
العنصر 2 — توفير البيانات
دائماً الصقوا بيانات حقيقية. لا تصفوها أبداً.
«هنا Entry Count وBounces وTotal Duration لأعلى 10 صفحات دخول لديّ: [PASTE CSV]»
CSV لا يحتاج أن يكون ضخماً — 10 صفوف تكفي لمعظم النماذج. ما يهم أن النموذج لديه أرقام حقيقية يُؤسس عليها التوصيات، لا «تخيّل متجراً نموذجياً» الذي يُنتج تلفيقاً.
نظافة الصيغة: الصقوا كنص عادي أو جدول markdown. كثير من أدوات الذكاء الاصطناعي تتدهور مع CSVs بصيغة Excel ذات علامات يساوي أمامية.
العنصر 3 — تأسيس المخطط
أخبروا النموذج بما تقيسه أداتكم وما لا تقيسه:
«هذه البيانات من Statnive، إضافة تحليلات WordPress بدون Cookies. تقوم بتتبع الزوار والجلسات والمشاهدات والمحيلات والتفاعل، لكنها لا تتبع الإيرادات أو أحداث التحويل أو بيانات الشراء لكل منتج (بعد). كل توصية يجب أن تكون قابلة للإجابة من الأعمدة التي قدّمتها للتو».
جملة «لا تتبع» هي السحر. تحجب النموذج من اقتراح تحليلات تتطلب بيانات لا تملكونها («احسبوا الإيرادات لكل جلسة بحسب القناة» — لا تستطيعون، لا تملكون إيرادات).
العنصر 4 — قيد المخرجات
افرضوا بنية. النموذج ينتج مخرجات أفضل حين يُقيَّد.
«أخرجوا كجدول من 3 أعمدة: page، hypothesis، experiment. اقتصروا على أعلى 3 صفحات دخول. كل فرضية يجب أن تشير إلى قيمة عمود محددة من بياناتي».
هنا يكسب سطر «يجب أن يشير إلى قيمة عمود محددة» قيمته — يحوّل النصيحة المبهمة إلى توصيات قابلة للتتبع والتحقق.
العنصر 5 — الإقرار بالتحفظات
أخبروا النموذج بما لا يستطيع معرفته:
«لا تستطيعون رؤية إنفاقي الإعلاني، هوامش الربح، حجم قائمة بريد العملاء، أو نموذج العمل. عاملوا مخرجاتكم كفرضيات لي للتحقق منها، لا أحكام. إن كانت البيانات غير كافية لاستخلاص استنتاج، قولوها صراحة».
هذا العنصر يُنتج المخرجات الأعلى قيمة المنفردة: «بيانات غير كافية للتوصية بـ X — يحتاج العمود Y للتقييم». النماذج التي لا تحصل على هذا التحفظ تلفّق إجابات واثقة بدلاً من ذلك.
نمط تسلسل النماذج (ونظافته)
النماذج المنفردة تجيب عن أسئلة منفردة. السلاسل تجيب عن أسئلة مركّبة.
المثال القانوني: تدقيق هدر الحملة.
المرحلة 1 — تدقيق جودة الحملة:
النموذج 4 من المكتبة. المدخلات: UTM source/medium/campaign + sessions/bounces/duration. المخرجات: حملات للتوسيع أو الإصلاح أو الإيقاف.
المرحلة 2 — تنظيف نظافة UTM:
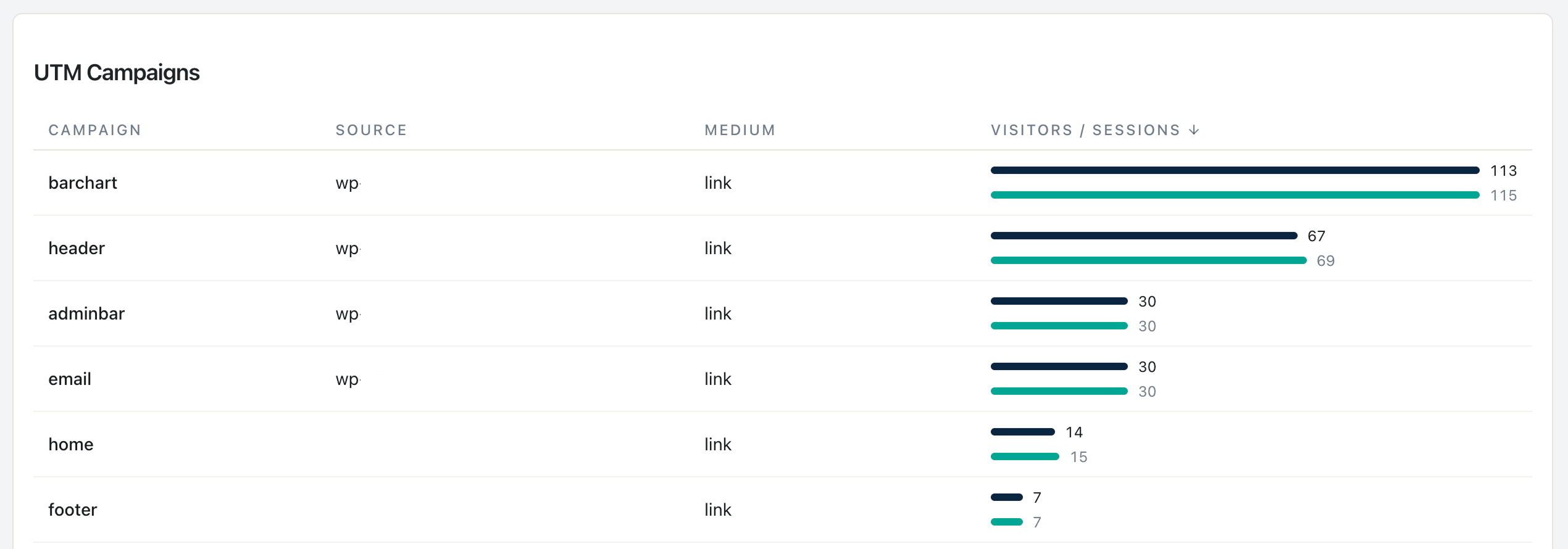
النموذج 5 من المكتبة. المدخلات: قيم UTM المميزة من آخر 90 يوماً. المخرجات: تعارضات الأحرف الكبيرة/الصغيرة، اقتراحات مخططات تسمية.
المرحلة 3 — قرار قائمة الإيقاف:
نموذج مخصص. المدخلات: قائمة «الإيقاف» من المرحلة 1 + قائمة «UTM مكسور» من المرحلة 2. المخرجات: القائمة النهائية للحملات التي يجب إيقافها فعلاً هذا الأسبوع، مع ملاحظة تشخيصية لكل حملة.
ثلاث مراحل، نتيجة واحدة (قائمة الإيقاف)، نسبة إشارة إلى ضجيج أعلى بكثير من طلب نموذج عملاق واحد لفعل الثلاثة.
نظافة السلسلة (القواعد المملة لكنها حرجة):
- أعيدوا ذكر الدور في كل مرحلة. لا تفترضوا أن السياق ينتقل — كل دور محادثة جديد يخاطر بإعادة الضبط.
- أعيدوا لصق شريحة البيانات التي تحتاجها كل مرحلة. لا تشيروا إلى «البيانات من قبل» — الصقوا المجموعة الفرعية ذات الصلة مرة أخرى.
- اقتبسوا المخرجات السابقة حرفياً. عند استخدام مخرجات المرحلة 1 كمدخلات للمرحلة 2، الصقوها كنص مقتبس. لا تلخّصوا.
- لا تتجاوزوا 4 مراحل دون مراجعة المالك. كل مرحلة تضيف انجراف؛ السلاسل الطويلة غير المراجَعة تراكم الأخطاء.
- توقّفوا عند أول مقياس مهلوس. إن اخترعت المرحلة 2 اسم عمود، أعيدوا البدء بتأسيس مخطط أحكم (العنصر 3). لا تستمروا في السلسلة.
أي نموذج لأي مهمة
تفصيل عملي بعد الاختبار عبر ChatGPT وClaude وGemini على مكتبة الـ 12 نموذجاً:
| المهمة | أفضل نموذج | السبب |
|---|---|---|
| توليد الفرضيات (واسع) | ChatGPT | الأكثر حدة في إنتاج فرضيات متنوعة |
| إجابات «لا أعرف» الصادقة | Claude | الأكثر معايرة حول عدم اليقين |
| الالتزام بمخرجات منظّمة | Gemini | الأفضل في البقاء ضمن صيغ JSON/الجدول |
| التحليل الكمي (الرياضيات) | ChatGPT مع Code Interpreter | يشغّل Python فعلاً، يلغي الأرقام المهلوسة |
| تحليل سياق طويل (أكثر من 10 آلاف توكن من البيانات) | Claude (Opus أو Sonnet) | الأفضل في الاحتفاظ بالسياق دون انجراف التلخيص |
| نموذج سريع لمرة واحدة | أيهما متاح | بصراحة، للنماذج القصيرة الفروق طفيفة |
الحالة الصادقة حيث يهزم SQL كل نموذج:
للأسئلة الكمية المحددة («ما معدل عملائي المتكررين؟»، «ما الإيرادات لكل جلسة لكل قناة؟»)، تشغيل SQL على قاعدة بيانات WooCommerce يُنتج الإجابة الصحيحة في مللي ثوانٍ. الذكاء الاصطناعي يستطيع الهلوسة؛ SQL لا يستطيع. استخدموا الذكاء الاصطناعي لتوليد الفرضيات والتعرف على الأنماط؛ استخدموا SQL للرياضيات الفعلية.
إن لم تكتبوا SQL، فإن Code Interpreter من ChatGPT (أو Claude مع أداة التحليل) يجسر الفجوة — يولّد SQL من نموذجكم، يشغّله على CSV لديكم، ويُرجع الإجابة مع الحساب مرئياً. هذا متميّز عن وضع الدردشة العادي حيث يخمّن النموذج الأرقام من السياق.
خط الخصوصية — ما الآمن للصق
صادرات Statnive نظيفة خصوصياً أصلاً:
- تقرير Pages — مسارات URL. آمن.
- تقرير Referrers — source/medium/campaign + domain. آمن.
- تقرير Geography — country/city/region. آمن.
- تقرير Devices — نوع الجهاز، المتصفح، نظام التشغيل. آمن.
أمور للتجريد قبل اللصق:
- عناوين URL لصفحات الشكر —
/order-received/12345/يحتوي معرّف طلب فريداً. استبدلوها بـ/order-received/[id]/قبل اللصق لتجنب تسريب معرّفات عبر مزوّدي الذكاء الاصطناعي. - عناوين URL تحمل أسماء العملاء — بعض الإضافات تنشئ عناوين حساب مستخدم مثل
/my-account/orders/john-smith-2024/. جرّدوا قطعة الاسم. - عناوين URL لاستعلامات البحث —
?search=customer's-personal-thingيمكن أن يسرّب القصد. جرّدوها إن لم تريدوها في بيانات تدريب الذكاء الاصطناعي.
لا شيء في تقارير Statnive يحتوي عناوين بريد أو IP أو معلومات دفع أو عناوين شحن. ما سبق حالات حافة لمعرّفات مسرّبة عبر مسار URL، لا محتوى التقارير الرئيسي.
لماذا يتفوق هذا على «اسألوا ChatGPT ما الخطأ في متجري»
أكثر نمط فشل شائع على r/WooCommerce وr/ChatGPT يبدو هكذا:
«متجري لا يحوّل. ماذا أفعل؟»
يستجيب النموذج بقائمة من 12 نقطة لنصائح CRO تجارة إلكترونية عامة. لا شيء منها قابل للتنفيذ على متجر المالك المحدد. يمشي المالك وهو يظن أن الذكاء الاصطناعي عديم الفائدة لـ CRO.
تشريح النموذج الخماسي العناصر يصلح هذا. نفس السؤال، منظّماً:

«أنتم محلل CRO لمتجر WooCommerce فردي يحقق 20000 دولار شهرياً. هنا بيانات قنوات آخر 30 يوماً من تقرير Referrers في Statnive (بدون Cookies، بدون GA4): [CSV]. Statnive لا يقيس الإيرادات أو أحداث المنتجات بعد. حدّدوا القنوات الـ 3 بأسوأ نسبة ارتداد/مدة. لكل واحدة، اذكروا 3 فرضيات تشير إلى بيانات الصف المحدد. أخرجوا كجدول. إن احتجتم بيانات لم أوفّرها للإجابة، قولوها صراحة».
نفس النموذج، نفس البيانات، مخرجات مختلفة بشكل دراماتيكي. البنية تقوم بالعمل.
ما يضيفه v1.0.0، وما لا يزال في خارطة الطريق
اعتباراً من v1.0.0 (مايو 2026)، يفتح Revenue Report نماذج الذكاء الاصطناعي الواعية بالإيرادات. مكتبة الـ 12 نموذجاً تدمج بيانات Revenue Report أصلاً: الإيرادات لكل قناة (النموذج 4)، تشخيص انخفاض القمع (النموذج 11)، تخصيص ميزانية الإيرادات لكل قناة (النموذج 12).
لا يزال في خارطة الطريق (فئة Growth، مخطط 2026):
- ملخص تنفيذي أسبوعي تلقائي بالذكاء الاصطناعي. تشغيل النماذج الـ 12 جميعها على بيانات متجركم وإرسال التقرير المدمج بالبريد — بدلاً من تشغيلكم لكل منها يدوياً. هذه ميزة فئة مدفوعة؛ سير العمل اليدوي مع نماذج النسخ واللصق يبقى مجانياً.
- نماذج مُحفَّزة بالشذوذ. عند رؤية Revenue Report انحرافاً ذا دلالة من أسبوع لآخر، تشغيل النموذج التشخيصي المقابل تلقائياً وعرض قراءة الذكاء الاصطناعي داخل
/wp-admin. أيضاً ميزة فئة Growth مخططة.
ما تفعلونه بعد ذلك
- ضعوا إشارة مرجعية على مكتبة الـ 12 نموذجاً.
- شغّلوا النموذج #1 (المراجعة الأسبوعية) هذا الاثنين على بيانات Overview لمتجركم.
- حين تكون المخرجات ضعيفة، دقّقوا أي من العناصر الخمسة كان مفقوداً من النموذج. عزّزوا وأعيدوا التشغيل.
- حين تحتاجون مسألة تحليل جديدة لا تغطيها المكتبة، استخدموا التشريح الخماسي لكتابة نموذجكم.
- للنظام التشغيلي الكامل لـ CRO، راجعوا الركيزة حول التحليلات التي تحترم الخصوصية لـ WooCommerce CRO.
الذكاء الاصطناعي لـ WooCommerce CRO يعمل — حين يكون النموذج منظّماً. النماذج العامة تنتج نصيحة عامة؛ النماذج المدركة لـ Statnive تنتج قرارات.